목차
1. Self-orthogonalizing adaptive filter
1. Self-orthogonalizing adaptive filter

DFT는 bandpass filter를 활용한 subband processing의 특수한 경우로 볼 수 있습니다. 따라서 filter bank나 prototype filter를 잘 설계하면 성능이 향상됩니다. 하지만 bandpass filtering 단계가 추가로 필요하고 설계가 복잡하다는 단점이 있습니다. 이를 보완하기 위해, low band과 high band를 반씩 나눠 처리하는 QMF(Quadrature Mirror Filter)를 많이 사용한다고 합니다.
Self-orthogonalizing adaptive filter는 두 단계로 구현되며, 여기서 orthogonalizing은 whitening과 동일하게 각 성분을 uncorrelated하게 만든다는 의미입니다. 즉, 입력 신호를 whitening한 후 LMS 알고리즘을 적용하는 방식으로 동작합니다. LMS 알고리즘과의 차이점은 학습률
Self-orthogonalizing adaptive filter는
2. DCT-LMS algorithm
DCT는 DFT에서 real part만 취한 것이고, imaginery part만 취하면 DST (Discrete sine transform)가 됩니다. DCT-LMS 알고리즘은 sliding window에서 DCT 계수를 구한 뒤, 각 계수의 파워 (

DCT-LMS 알고리즘에 대해 좀 더 자세히 살펴보겠습니다.
3. Subband adaptive filter
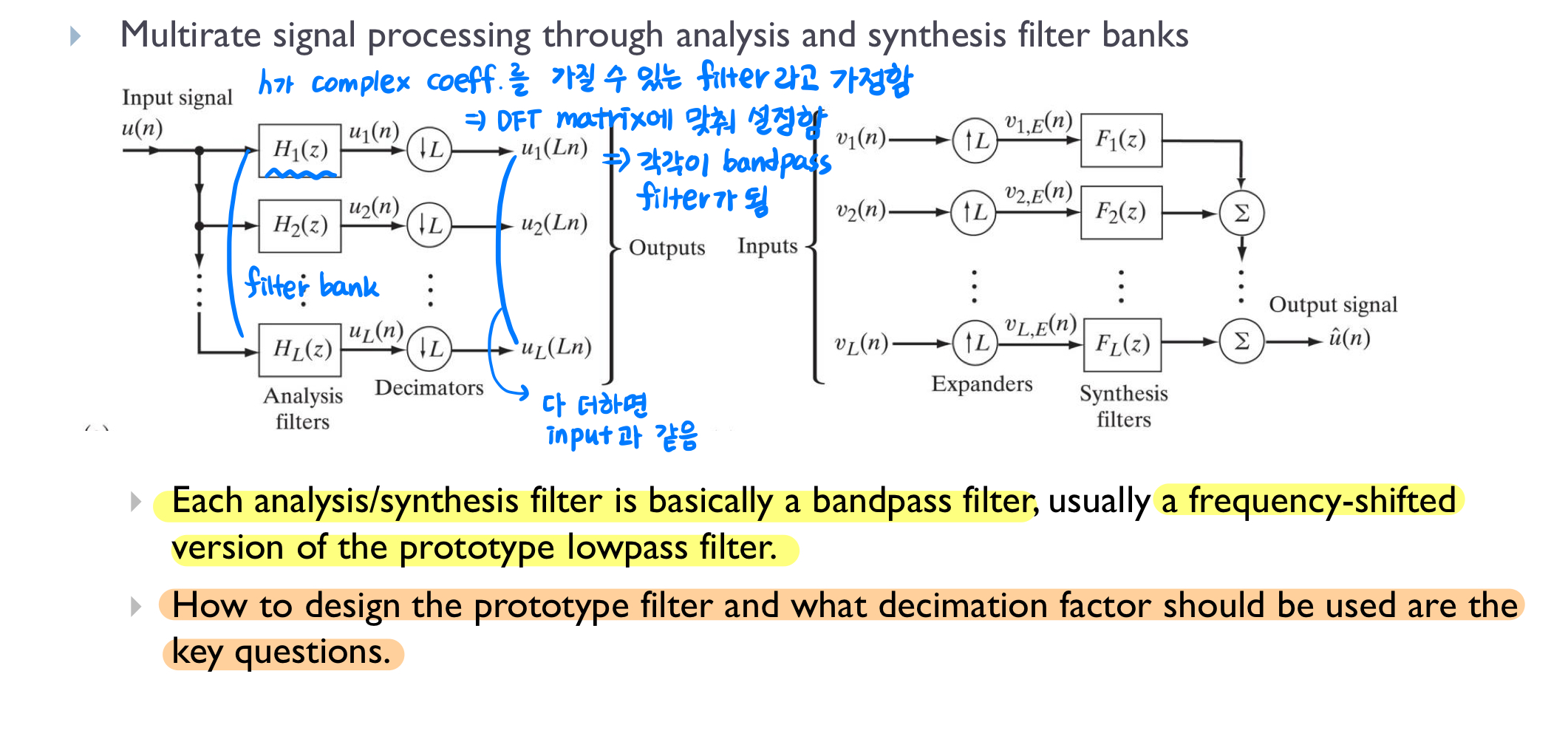
Frequency domain processing은 각 주파수 성분을 개별적으로 처리할 수 있어 time domain processing에 비해 유리한 점이 있습니다. Subband adaptive filter는
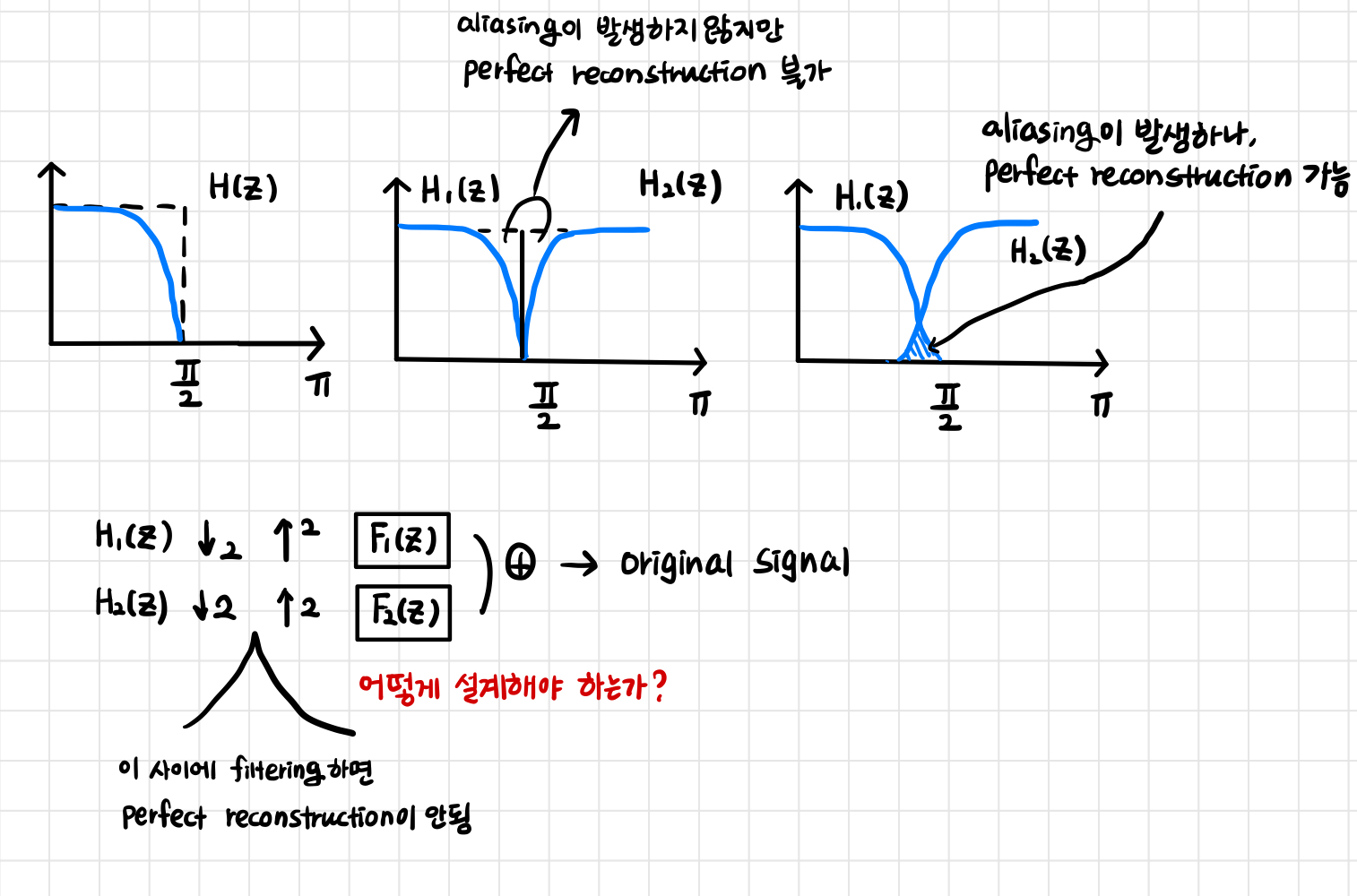
Subband adaptive filter에서 decimation factor는 각 low band signal을 얼마나 downsampling할지를 결정합니다. 다운샘플링을 통해 계산량을 줄일 수 있지만, decimation factor가 너무 크면 대역 간 에일리어싱이 발생할 수 있으므로 적절한 설정이 필요합니다.
다운샘플링 (Downsampling)
sampling rate을 변환하는 이유가 뭔지 생각해보고 샘플링 속도를 줄이는 방법인 downsampling에 대해 알아봅시다. Sampling rate 변환 연속 시간 신호의 새로운 이산 시간 표현을 얻기 위해 이산 시간 신호
sunny-archive.tistory.com
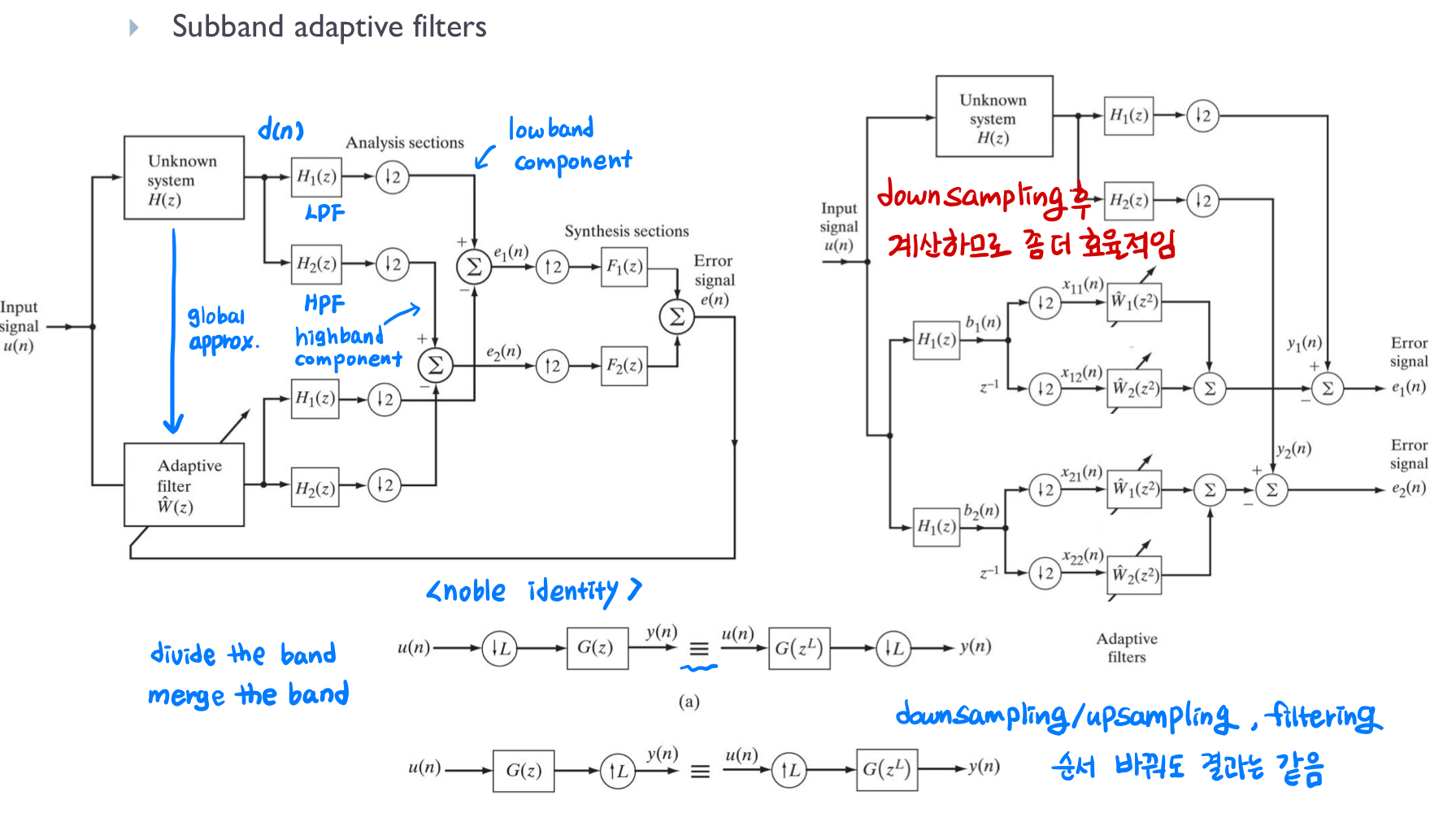
왼쪽 그림은 low band, high band로 분할한 후 따로 error를 계산하여 합산합니다. 오른쪽 그림은 홀수 번째, 짝수 번째 샘플들을 개별적으로 처리한 후 decimation을 수행하고 있습니다. 이 과정에서 noble identity를 활용하여 decimation과 filtering 연산의 순서를 바꾸면 계산량을 줄일 수 있습니다. noble identity를 적용하지 않은 방식에서는, decimation 전의 모든 샘플에 대해 필터링을 수행하므로 0인 계수와도 계속 곱셈을 해야 해서 convolution 연산이 비효율적입니다. 하지만 noble identity를 이용해 downsampling하고 filtering하면 처리해야 할 샘플 수가 줄어들기 때문에 효율적인 연산이 가능합니다.
결과적으론 두 그림 모두 똑같은 결과를 출력하지만 오른쪽은 fast Block LMS 알고리즘처럼 learning rate을 서로 다른 band에서 다르게 줄 수 있고 주파수 대역별로 따로 adaptation을 시켜줄 수 있기에 time domain보다 더 좋은 필터링 결과를 얻을 수 있습니다.
GIST 신종원 교수님 '적응신호처리' 수업 자료를 바탕으로 쓴 글입니다.
'연구 노트 > 적응신호처리' 카테고리의 다른 글
| Recursive Least-Square (RLS) Adaptive Filter 정리 (1) | 2024.12.13 |
|---|---|
| 최소제곱법 (Least Square Method) 정리 (0) | 2024.12.12 |
| Fast block LMS 알고리즘 이해하기 (2) | 2024.10.26 |
| Least-Mean-Square Adaptive Filter (LMS) 알아보기 (1) | 2024.10.24 |
| Gradient Descent를 위한 최적화 알고리즘 (0) | 2024.10.23 |



