목차
1. Block adaptive filter

Block adaptive filter는
2. Fast block LMS algorithm
Fast block-LMS 알고리즘은 주파수 영역에서 FFT를 사용하여 구현됩니다. convolution 식
* Overlap-add method
아주 긴 신호가 입력으로 들어왔을 때, 이 신호를
* Overlap-save method
Overlap-save method는 각 블록에서 생긴 circular convolution artifact를 잘라버리고 안전한 부분만 쓰는 방법입니다. 안전한 부분이
Overlap-save method를 좀 더 자세히 알아보도록 하겠습니다. 살펴보기에 앞서, DFT와 circular convolution에 대한 사전지식이 필요합니다. 아래 링크에서 관련 내용을 참고해주세요 :)
DFT (Discrete Fourier Transform) 바로 알기
이산 푸리에 변환 (DFT)의 정의와 특성, 그리고 중요한 개념인 circular convolution에 대해 알아보고 예제를 통해 개념을 정리해봅시다. DFT를 쓰는 이유DFS (Discrete Fouirer Series)는 신호가 주기적인 성
sunny-archive.tistory.com
선형 컨볼루션 (Linear convolution)과 원형 컨볼루션 (Circular convolution)
선형 컨볼루션과 원형 컨볼루션의 개념에 대해 알아보고 파이썬 코드로 구현해 봅시다. Linear convolution linear convoluton은 주어진 두 개의 이산 시간 신호를 이용하여 새로운 신호를 생성합니다.
sunny-archive.tistory.com
DTFT의 결과는 주파수 축에서 연속적이기 때문에 컴퓨터가 직접 처리하기 어렵습니다. 따라서 디지털 신호를 처리하기 위해 연속적으로 존재하는 주파수를 쪼개서 이산적인 값으로 만드는 DFT를 사용합니다. 다시 말해, DFT는 DTFT를 주파수 영역에서 샘플링한 것으로, 이 과정에서 시간 영역에서는 aliasing이 발생하고, 이는 circular convolution으로 나타납니다. (뒤집힌 후 겹쳐져서 들어옴)

만약

Fast block LMS 알고리즘은 주파수 영역에서 신호처리를 위해 FFT를 사용하여 필터를 적용하고 Overlap-save method를 통해 circular convolution artifact를 제거한 후 filter weight을 업데이트합니다.
입력 신호의 길이
Block LMS 알고리즘과 마찬가지로 weight를 업데이트하지만, fast block LMS 알고리즘에선 circular convolution artifact를 제거하기 위해
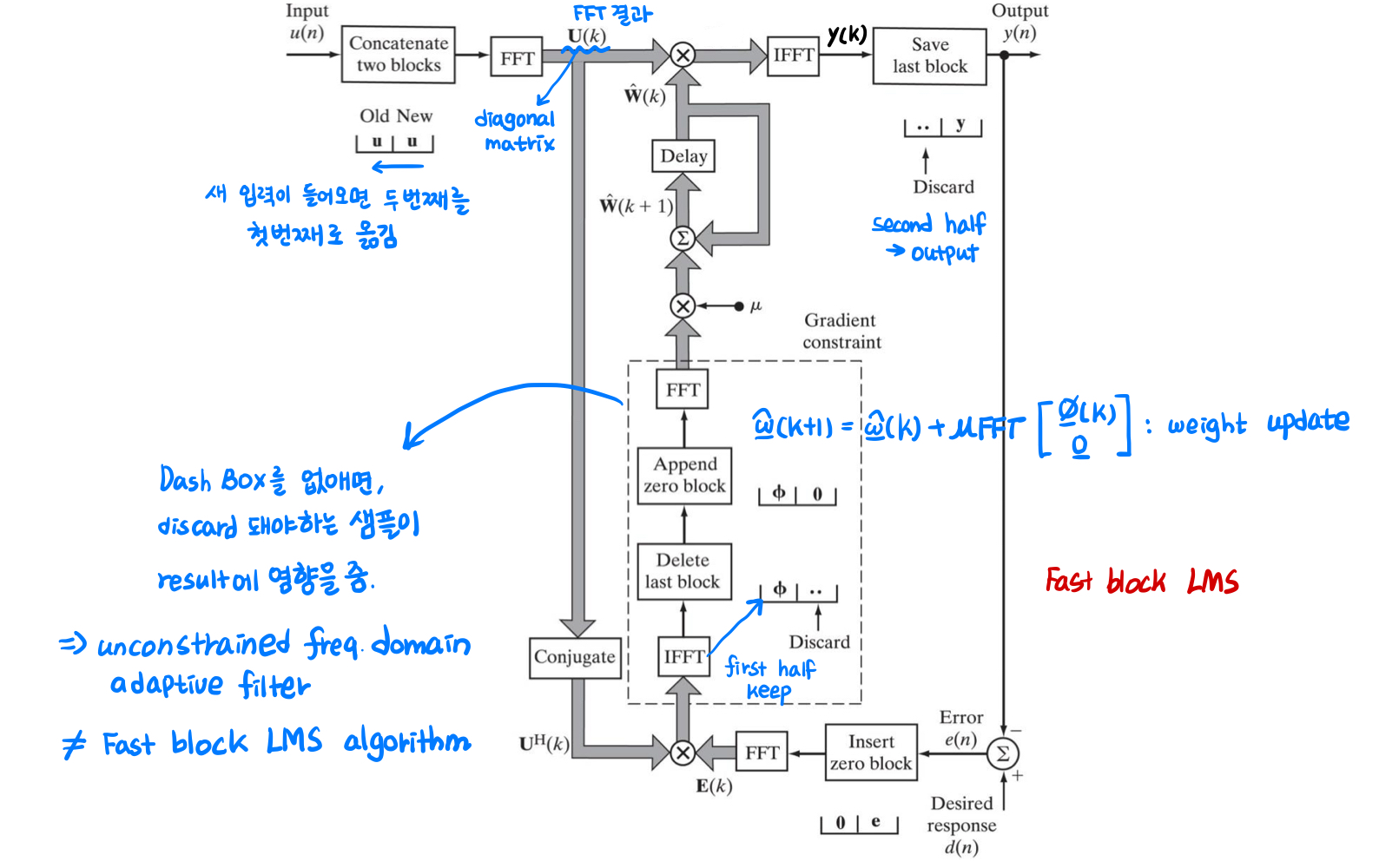

Fast block LMS 알고리즘에서 'fast'는 FFT의 빠른 계산을 의미하며, 수렴 특성 자체는 block LMS 알고리즘과 동일합니다. 그러나 Fast block 알고리즘의 수렴 속도는 각 주파수에 다른 step size,

Unconstrained frequency-domain adaptive filter는 fast block LMS 알고리즘에서 보았던 dash box를 없앤 것이라고 이해할 수 있습니다. circular convolution artifact를 0으로 깔아 제거해주었던 과정을 생략한 것으로, 이로 인해 간단하고 계산량도 줄어들지만 기존의 fast block LMS 알고리즘과는 다른 결과를 얻게 됩니다.
GIST 신종원 교수님 '적응신호처리' 수업 자료를 바탕으로 쓴 글입니다.
'연구 노트 > 적응신호처리' 카테고리의 다른 글
| 최소제곱법 (Least Square Method) 정리 (0) | 2024.12.12 |
|---|---|
| Frequency-Domain & Subband Adaptive filter 정리 (1) | 2024.10.28 |
| Least-Mean-Square Adaptive Filter (LMS) 알아보기 (1) | 2024.10.24 |
| Gradient Descent를 위한 최적화 알고리즘 (0) | 2024.10.23 |
| Steepest descent Method 총정리 (0) | 2024.10.22 |



