Steepest descent algorithm은 기울기(gradient)를 따라 함수 값을 최소화하는 최적화 알고리즘입니다. 주어진 함수에서 현재 위치의 기울기 반대 방향으로 이동하며 함수 값이 가장 빠르게 감소하게 됩니다. 각 단계에서 step size에 따라 이동하며, 기울기가 0에 가까워질수록 최적점(optimal point)에 수렴합니다.
2. Steepest-Descent algorithm의 Stability
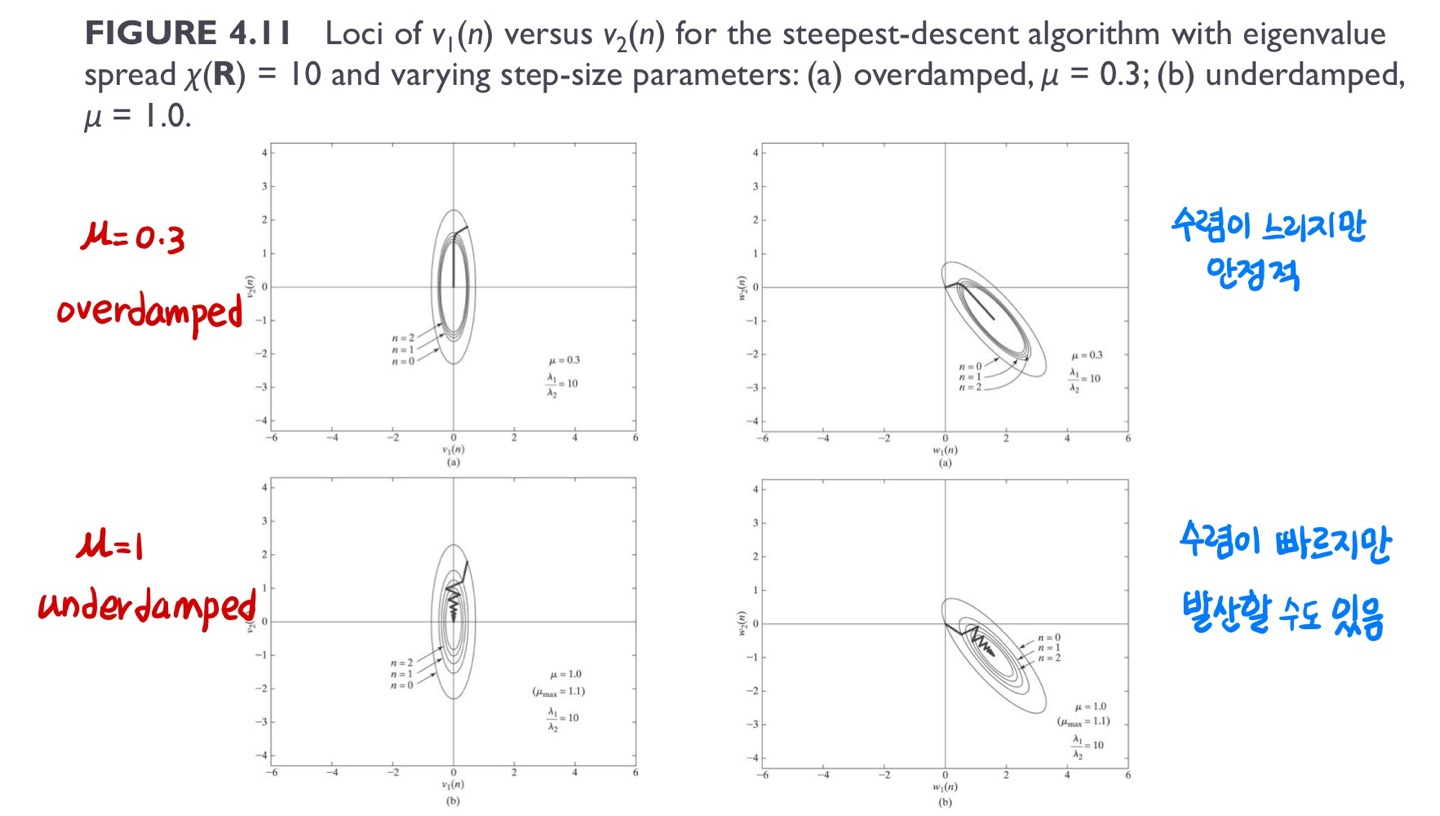
Step size μ는 너무 작으면 최적점에 느리게 수렴하고, 너무 크면 발산할 수 있어 적절한 값을 선택하는 것이 중요합니다. 위 예시에서는 c(n)이 원점에 있을 때가 가장 optimal하다고 가정합니다.
vk(n) 식을 geometric series로 표현하여 각 time step에서 값이 exponential하게 감소함을 나타낼 수 있습니다. 여기서 μ가 0과 2λmax 사이에 있어야 vk(n)이 수렴할 수 있습니다. vk(n)의 convergence와 관련된 시간 τk를 정의하고, 이 식을 J(n)에 적용하면 MSE가 최소화될 때까지 걸리는 시간을 대략적으로 계산할 수 있습니다.
3. (Example) 2nd order real-valued AR process
2차 auto-regressive (AR) process이 위 식과 같을 때, 예시를 살펴보겠습니다. ν(n)은 white gaussian noise이기 때문에, 현재 시점에만 영향을 주고 과거에는 영향을 미치지 않습니다.
2차 AR process에서 a1,a2 coefficient를 알고 싶을 때, 과거의 입력 신호를 순서대로 곱한 후 expectation을 취함으로써, 각 delay에 따른 autocorrelation을 구할 수 있습니다. 이를 통해 일련의 계산을 거쳐 r(0)을 AR coefficient인 a1과 a2에 대한 식으로 나타낼 수 있게 됩니다.
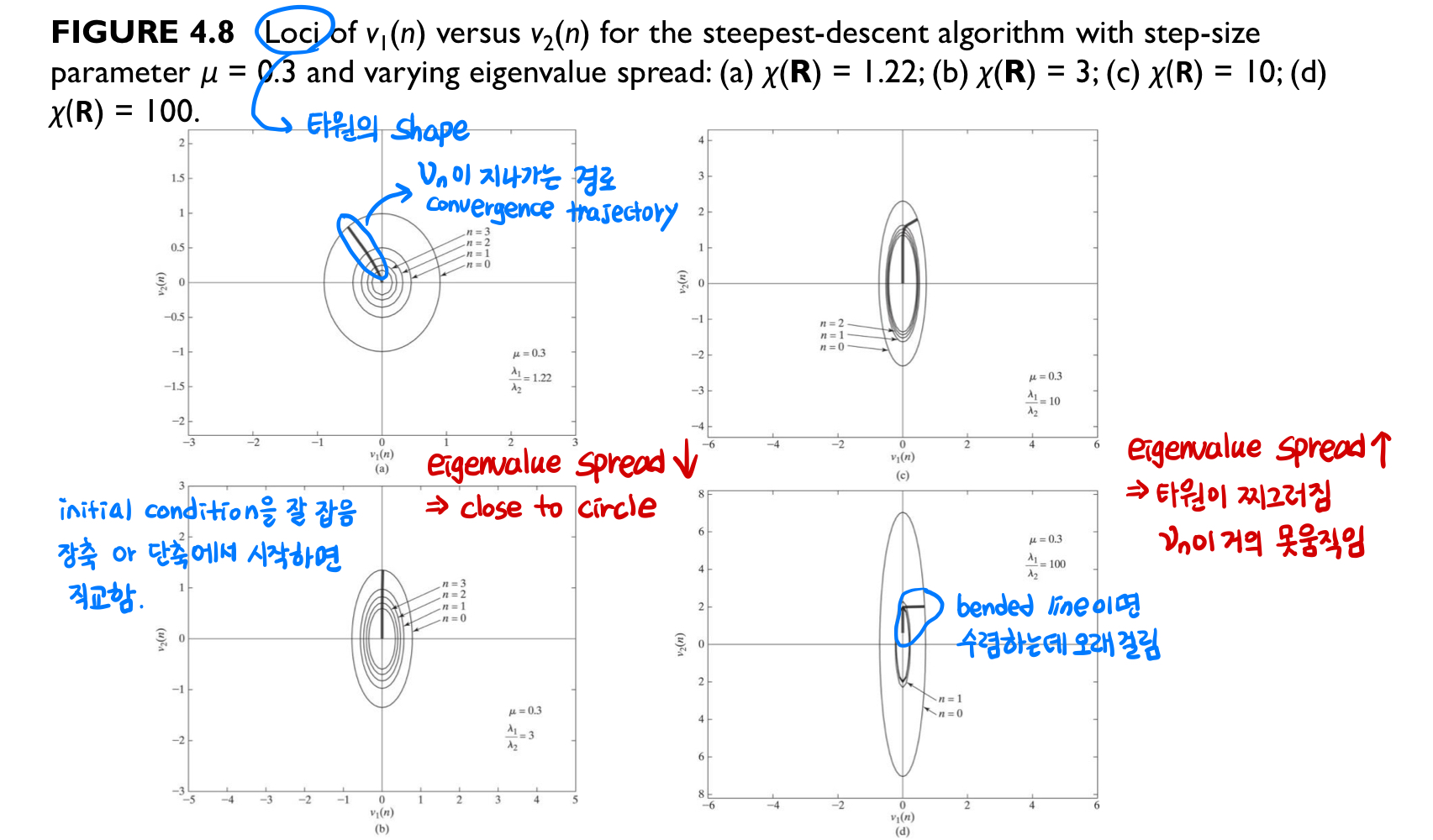
R은 autocorrelation function r(0)과 r(1)을 기반으로 계산되며 σ2u는 input signal의 variance를 나타냅니다. autocorrelation matrix의 eigenvalue는 R에서 determinant det(R−λI) 식을 통해 구합니다. eigenvalue spread는 두 eigenvalue 간 크기 비율을 나타내는 지표입니다. Error function J(n)은 타원 형태의 error 곡선으로 나타낼 수 있는데 여기서 v1과 v2는 각각 eigenvector에 따른 좌표 성분을 나타냅니다. 각 축은 eigenvalue에 비례하기 때문에 그에 따라 error가 다른 속도로 감소합니다.
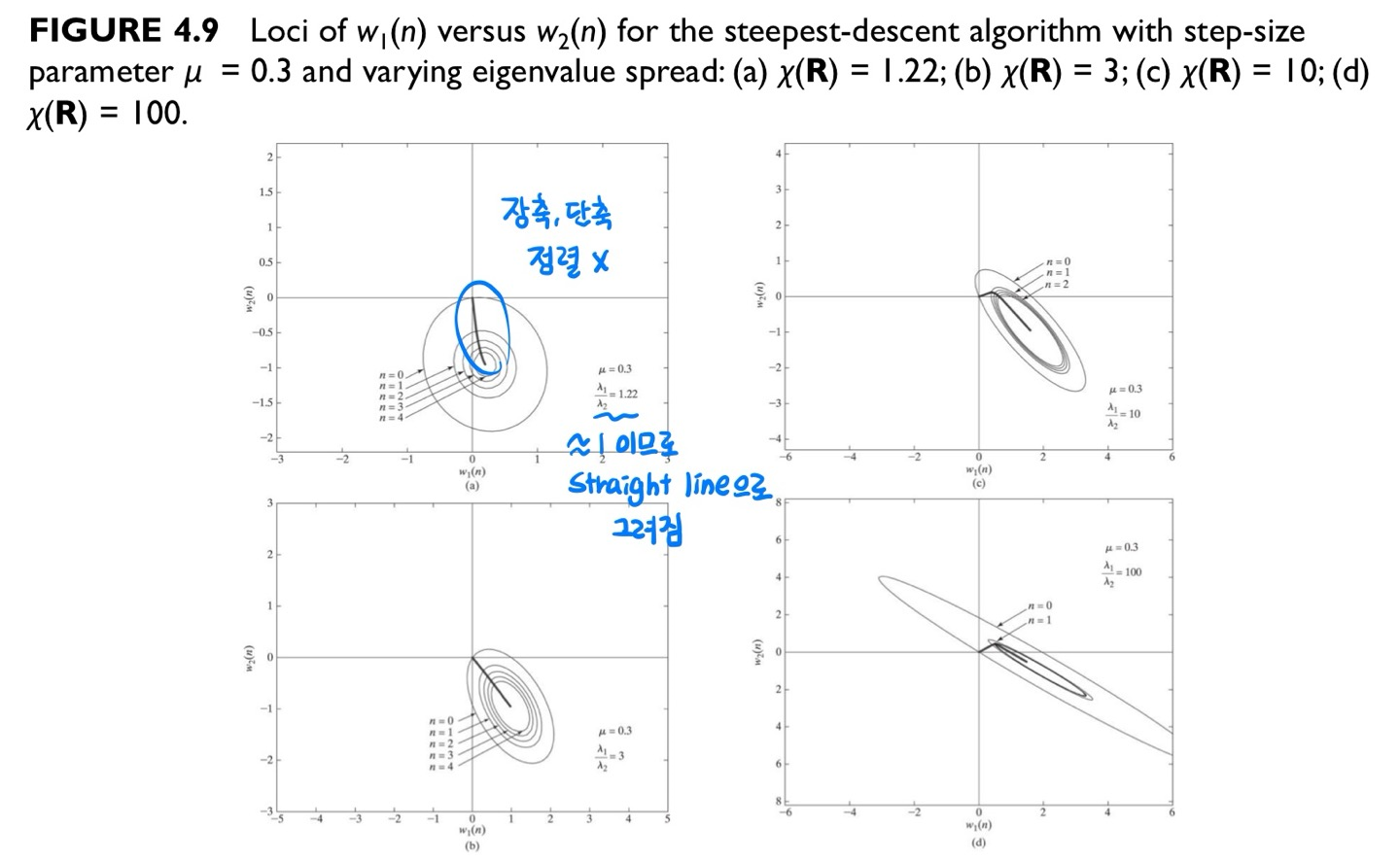
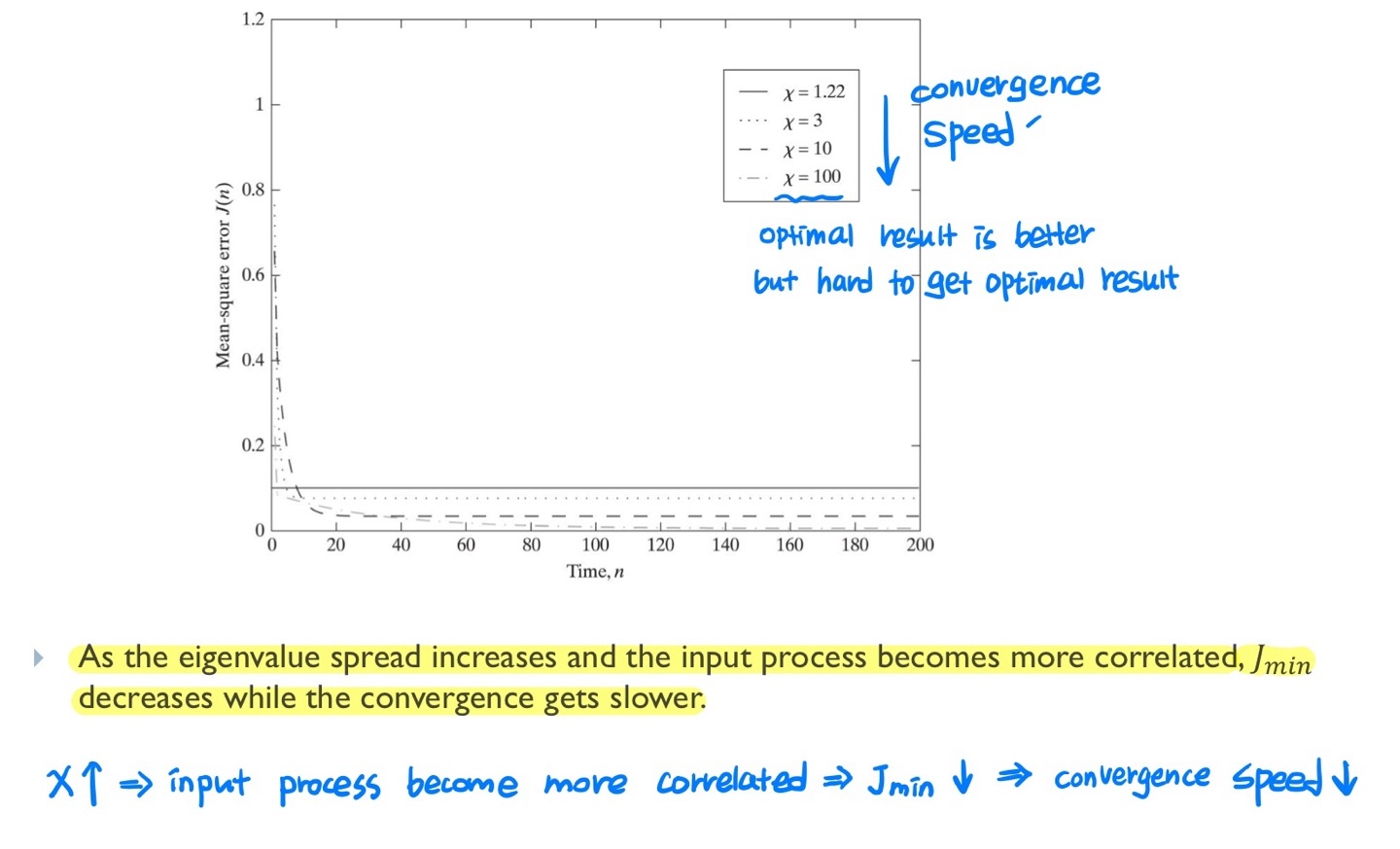
desired signal에 optimal filter output을 뺐을 때 white noise power만 남게 됩니다. AR coefficient a1과 a2를 이용해 Jmin 값을 나타낼 수 있습니다. Jmin은 eigenvalue spread χ 값이 증가할수록 감소합니다. vk(n)은 시간에 따라 filter weight가 어떻게 shift되고 rotate 되는지 보여주는 업데이트 식으로, n=0을 대입하면 초기 상태 값을 알 수 있습니다.
J(n)은 고정된 상태로, 모든 J(n) 값을 average하여 최적값에 수렴하는 선 (convergence trajectory)을 그려주었습니다. eigenvalue spread 값이 작을수록 원에 가까운 모양을 가지고 여기에 더해 initial 값이 장축이나 단축에 위치한다면 거의 직선 경로로 빠르게 수렴하는 것을 볼 수 있습니다. 반대로, eigenvalue spread 값이 클 때, 찌그러진 타원 모양에 vn도 거의 움직이지 않아 수렴 속도가 매우 느려진 것을 관찰할 수 있습니다.
시간에 따른 J(n) 값을 나타낸 것인데, eigenvalue spread가 클수록 input process가 특정 성분에 치우져져 있어 상대적으로 correlation이 더 커지는 경향이 있으며, 예측은 잘되지만 수렴 속도가 느린 걸 확인할 수 있습니다.
overdamped란 최적점에 도달하는데 시간이 오래 걸리지만 안정적으로 수렴하는 상태를 말합니다. underdamped는 상대적으로 weight 변화량이 더 커서 수렴 속도가 빠르지만, learning rate가 필요 이상으로 커지면 발산합니다. 어느 것이 더 빠른지는 그림만 보고는 알 수 없는 문제로, 수렴 속도와 예측 정확도를 고려하여 적절한 learning rate 값을 설정해주는 것이 중요합니다.