목차
1. Stochastic gradient descent (SGD)
3. Nestrov accelerated gradient (NAG)
10. Cosine Annealing with Warm Restart
1. Stochastic gradient descent (SGD)

Gradient Descent 알고리즘은 오류 함수의 기울기(미분)를 계산해 이를 바탕으로 파라미터를 업데이트하여 최적점을 찾는 방법입니다. Gradient Descent에는 두 가지 방식이 있는데, Steepest Descent 알고리즘은 전체 데이터를 사용해 기울기를 계산하는 반면, Stochastic Gradient Descent (SGD) 알고리즘은 데이터의 부분집합(mini-batch)을 사용한다는 차이점이 있습니다. Steepest Descent 알고리즘은 정확하지만 데이터가 클 경우 계산량이 많다는 문제를 가지고 있는데 이를 완화하기 위해 SGD는 소량의 샘플만을 가지고 기울기를 계산합니다.
- saddle point: gradient가 0인 지점으로, 일부 방향에서는 최솟값처럼 보이지만 다른 방향에서는 최댓값처럼 보임
하지만, SGD도 적절한 learning rate 설정이 어렵다는 문제가 있습니다. 그리고 learning rate를 조정할 때, 특정 조건이나 반복 횟수에 따라 변경할 기준을 미리 설정해야 합니다. 또한, learning rate가 scalar일 경우 모든 파라미터에 동일한 값이 적용되는 게 비효율적일 수 있으며 saddle point로 인해 최적점인 global minima를 추정하지 못하는 등 정확한 계산이 어려울 수 있습니다.
2. Momentum
gradient가 0인 saddle point에 갇히면 더 이상 파라미터가 업데이트되지 않습니다. saddle point에서 탈출하고 최적점에 빨리 수렴하도록 SGD를 보완하기 위해, Momentum이 등장했습니다. Momentum은 단순히 현재 기울기만 따르는 게 아니라, 최근에 계산된 gradient 값의 평균치를 바탕으로 원래 가던 방향에 더 가중치를 주는 방법입니다. momentum term
3. Nestrov accelerated gradient (NAG)
NAG는 momentum과 유사하지만, gradient가 현재 파라미터값과 momentum term을 더한 값으로 계산됩니다. 이 값은 업데이트된 파라미터의 근사값으로 활용됩니다.
4. Adagrad
Adagrad는 파라미터 벡터
5. RMSProp
RMSProp은 Adagrad에서의
6. Adadelta

SGD나 momentum 알고리즘에서 cost function이 unit이 없고 (무차원), 파라미터가 가정된 unit을 가지고 있다면, 파라미터 업데이트 unit은 해당 파라미터 unit의 역수가 됩니다. Adagrad에서는 업데이트 unit이 무차원 값이 되지만, Adadelta에서는 파라미터 업데이트 unit이 파라미터 자체 unit과 동일합니다. 이 가정은 classification에 많이 사용되는 cross-entropy 같은 cost function에는 적합하지만, regression task에서 쓰이는 mean square error 같은 cost function에는 적합하지 않을 수 있습니다.
7. Adam

Adam은 각각의 파라미터에 대해 1차 moment (gradient average)과 2차 moment (gradient square average) 값을 추적하여 learning rate을 adaptive하게 조정합니다.
8. Adamax

Adam 알고리즘에서는 파라미터 업데이트가 이전과 현재 gradient의
9. Noam decay

Noam decay는 Transformer에서 사용되는 learning rate schedule입니다. Adam optimizer를 기반으로 learning rate
10. Cosine Annealing with Warm Restart
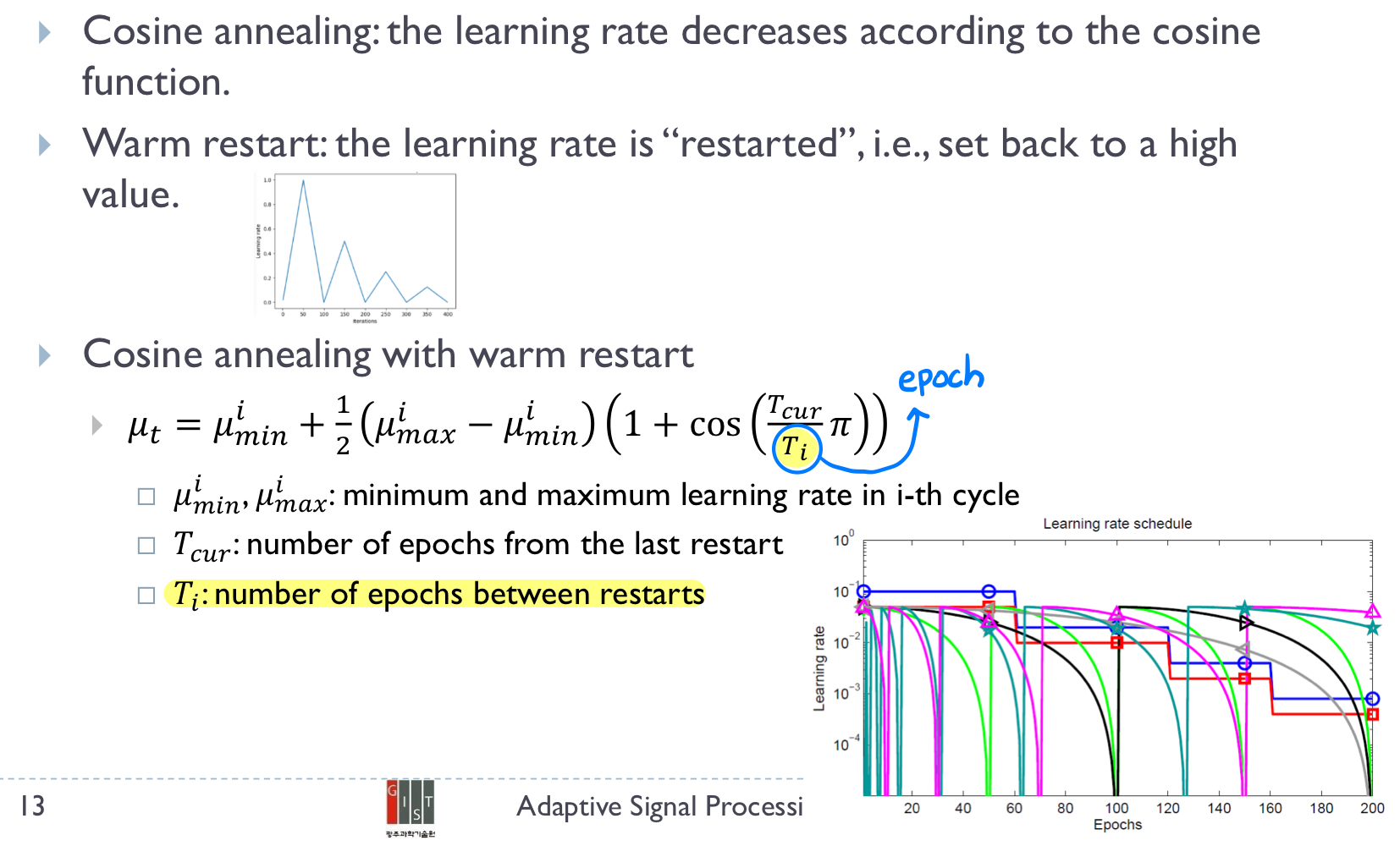
Consine Annealing은 학습이 진행됨에 따라 learning rate가 cosine 함수 형태로 감소하다가, 주기적으로 높은 값으로 다시 리셋 (warm restart)되는 방식입니다. local minima에 갇혀도 warm restart를 통해 특정 learning rate 값으로 돌아감으로써 탈출할 수 있습니다.
GIST 신종원 교수님 '적응신호처리' 수업 자료를 바탕으로 쓴 글입니다.
'연구 노트 > 적응신호처리' 카테고리의 다른 글
| Fast block LMS 알고리즘 이해하기 (2) | 2024.10.26 |
|---|---|
| Least-Mean-Square Adaptive Filter (LMS) 알아보기 (1) | 2024.10.24 |
| Steepest descent Method 총정리 (0) | 2024.10.22 |
| Linear Prediction 바로 알기 (0) | 2024.10.21 |
| Wiener filter 총정리 (0) | 2024.10.19 |



