대표적인 adaptive beamforming 기법인 MVDR (Minimum Variance Distortionless Responses) beamformer에 대해 살펴보겠습니다.
Beamforming
신호에 weight를 곱해서 특정 방향으로부터 온 원하는 소스 신호를 강화하고 그 외의 방향에서 온 노이즈는 억제하는 것을 beamforming이라고 합니다. beamformer는 spatial filter라고도 하는데 frequency dependent한 벡터

desired signal을 가르킬 빔 (beam)은 compelx plane 상에서 나타낼 수 있는 gain (파워), phase (방향) 값을 최적의 값으로 조정함으로써 형성할 수 있습니다. 위와 같이, 원하는 빔패턴을 얻기 위해 조절하는 가중치 값들을 다 모으면 weight vector, 앞서 말했던
윈도우의 길이가 충분히 긴 Narrowband model임을 가정했을 때, 빔포머의 weight는 MMSE (Minimum mean squared error) criterion에 따라 최적화됩니다.
Adaptive beamforming
전통적인 빔포머 (conventional beamformer)는 noise 존재 유무에 상관없이 side lobe 조절을 위해 낮은 gain 값을 가지고 원하는 신호의 방향으로 phase가 shift된 모양으로 빔을 형성하였습니다. 이와는 반대되는 개념인 adaptive beamformer는 받은 데이터의 통계치에 따라 weight를 조정합니다. 실제 환경에 adaptive하기 때문에 noise가 존재하는 실생활에 최적화된 빔패턴을 생성하는 weight를 계산할 수 있습니다. 이어서 adaptive beamforming의 대표적인 알고리즘인 MVDR에 대해 알아보겠습니다.
* adaptive: 시간에 따라 변화하는 데이터나 환경에 대응하여 적응할 수 있는 성질을 말함
MVDR beamformer
MVDR 빔포머 (Minimum Variance Distortionless Responses)는 신호의 gain을 그대로 유지한다는 제약조건 (신호 왜곡 X) 하에, noise variance 값을 최소화하는 output 값이 나오도록 설계된 빔포머를 말합니다.
수식에서 볼 수 있듯이, 원하는 신호가 왜곡 없이 그대로 나온다는 제약조건 하에 noise signal의 covariance matrix를 최소화하는 weight를 계산할 수 있습니다. MVDR 빔포머 solution 유도 과정을 보고 싶다면, 아래 링크를 타고 들어가심 됩니다.
MVDR Beamformer 유도 (Feat. 라그랑주 승수법)
Narrowband라고 가정했을 때, MVDR beamformer를 라그랑주 승수법 (Lagrange Multiplier Method)을 이용해 직접 풀어봅시다. * Note! (소문자: scalar, 볼드체 소문자: vector)로 표기하였습니다. / 필기본에서는 notation
sunny-archive.tistory.com
FMVDR beamformer
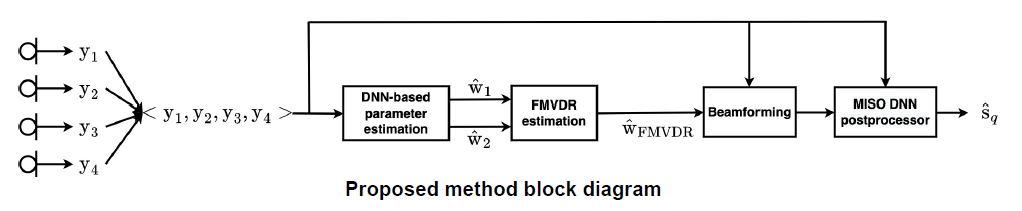
이 내용은 저희 연구실 선배 논문에서 가져왔습니다 [2]. speech와 noise의 spatial covariance matrix (공간 공분산 행렬)을 추정할 때 주로 time-average를 취해서 계산하는데 이 방식이 phase 정보를 왜곡시켜 빔포머의 성능이 최적화되지 않는 문제가 발생한다고 합니다. 이 문제에 대한 솔루션으로 논문에서 제안한 방법은 기존의 MVDR을 아래와 같이 factorized form으로 정리하는 것이었습니다. 이 아이디어를 통해, 딥러닝이 추정할 parameter 수를 2개로 줄이고 복잡한 행렬 계산 (matrix inversion, eigen decomposition)을 줄이면서 clean speech 추정 성능도 높일 수 있다고 합니다. 관심 있으신 분들은 참고하시면 좋을 것 같아서 추가로 적어보았습니다.
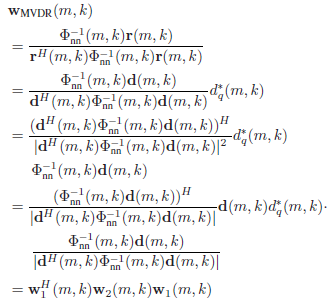
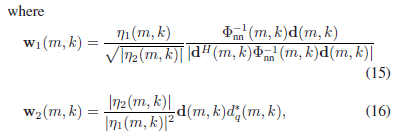

Reference
[1] S. Gannot, E. Vincent, S. Markovich-Golan, and A. Ozerov, “A Consolidated Perspective on Multimicrophone Speech Enhancement and Source Separation,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 25, no. 4, pp. 692–730, Apr. 2017, doi: https://doi.org/10.1109/taslp.2016.2647702.
[2] H. Kim, K. Kang, and Jong Won Shin, “Factorized MVDR Deep Beamforming for Multi-Channel Speech Enhancement,” IEEE Signal Processing Letters, vol. 29, pp. 1898–1902, Jan. 2022, doi: https://doi.org/10.1109/lsp.2022.3200581.
[3] “An introduction to Beamforming,” www.youtube.com. https://www.youtube.com/watch?v=VOGjHxlisyo&t=111s (accessed Mar. 12, 2024).
[4] “Radiation pattern,” Wikipedia, Feb. 14, 2023. https://en.wikipedia.org/wiki/Radiation_pattern
'연구 노트 > 음성신호처리' 카테고리의 다른 글
| 2024.04.11 신입생 세미나 Hearing, Auditory Models, and Speech Perception 2/2 질문 정리 (0) | 2024.04.11 |
|---|---|
| Wiener filter: 신호 필터링, 예측을 하는데 쓰는 linear filter (2) | 2024.03.13 |
| Multi-Channel 신호처리 & 빔포밍 (Beamforming)에 대한 고찰 (1) | 2024.03.07 |
| FFT 수행 시 zero padding이 frequency resolution에 미치는 영향 (0) | 2024.02.14 |
| 음성신호처리에서 Pre-emphasis filtering을 하는 이유 (1) | 2023.11.10 |



