목차
0. Summary
노이즈가 많고 잔향이 있는 까다로운 음향 환경에서 source localization을 수행하기 위해, 공간적 특징 (spatial feature)을 효과적으로 추출하는 것이 중요합니다. 본 논문 [1]의 베이스라인으로 사용된 FN-SSL [2]에서는 LSTM 기반 모델이 충분히 좋은 single moving source localization 성능을 보여주었습니다. 이 논문에선 scalable SSM (State space model) 기반의 Mamba 모델을 localization task에 적용한 TF-Mamba 모델을 제안하며, 다양한 시퀀스 데이터에서 우수한 성능을 보이는 Mamba의 장점을 활용하여 더욱 정확한 single source localization을 수행합니다. TF-Mamba는 time 및 frequency feature를 융합하여 음성 신호로부터 spatial feature를 뽑아내고 bidirectional Mamba를 이용해 time, frequency별로 처리합니다. 이는 FN-SSL 모델에서의 LSTM block을 Bi-Mamba Block으로 교체한 것으로, TF-Mamba는 linear complexity를 잘 유지하면서 오디오 시퀀스의 context modeling을 개선합니다.
- Scalable SSM: 시퀀스의 길이나 데이터의 양이 증가하더라도 성능이나 효율성을 유지하면서 적용할 수 있음
- linear complexity: 계산 복잡도가 입력 데이터의 크기에 비례하여 선형적으로 증가하는 것
1. Proposed TF-Mamba
Mamba는 Transformer와 견줄 수 있을 정도로 높은 성능을 가진 모델로, 다양한 시퀀스 기반 모달리티에 적용 가능합니다. 음성 및 오디오 신호는 waveform과 spectrogram에서 sequential한 특성을 지니기 때문에, 효과적으로 Mamba를 활용할 수 있습니다. 현재 Mamba는 음성 향상, 인식, 합성 등 음성 관련 작업에 주로 사용되고 있지만, 음원 위치 추정 분야에서 SSM을 활용한 효율적인 모델 설계에 관한 연구는 아직 부족한 상황입니다.
1-1. Mamba
Structured SSM은 적은 연산량과 메모리를 가지고 long dependent sequence를 효율적으로 처리할 수 있습니다. 이러한 특성 덕분에 Transformer와 RNN 아키텍처를 대체할 새로운 가능성을 보여줍니다. Mamba는 input-dependent selection mechanism을 도입하여 들어오는 정보를 효과적으로 필터링하고, hardware-aware algorithm을 통해 시퀀스 길이에 따라 linear하게 확장되어 SSM 성능을 향상시킵니다.
Mamba의 아키텍처는 SSM block과 linear layer를 결합하여 구성됩니다. 구조는 단순하지만 다양한 long sequence task에서 SOTA 성능을 보여주며, training과 inference 과정에서 계산 효율성이 꽤 좋습니다.
Mamba의 핵심 요소는 linear selective SSM 입니다. 아래 식에서
Mamba의 linear한 성질로 인해, 길이가
Unidirectional Mamba는 gated linear layer 사이에 위치한 State space model 입니다. 대부분의 음성 관련 task에서는 과거와 미래 시퀀스 정보를 모두 캡처할 수 있는 bidirectional 모델링을 선호하기 때문에, 본 논문에서는 2 개의 SSM과 causal convolution이 parallel하게 실행되는 BiMamba를 사용합니다. 두 개의 SSM은 각각 original sequence와 reverse sequence를 처리해 얻은 output을 평균 처리함으로써 양방향에서 수집된 정보를 통합합니다.
1-2. Network Architecture

네트워크 입력으로 STFT(Short-Time Fourier Transform) 계수의 실수부와 허수부가 들어오므로, 입력 채널은 마이크 개수의 2배가 됩니다. 모델은 3개의 모듈로 구성되어 있습니다: Feature Encoder, Time-Frequency Mamba, 그리고 Output Decoder입니다.
* Feature Encoder
spectral property를 향상하기 위해, 입력은 feature encoder를 통해 처리되며 2개의 convolutional layer를 옆에 붙인 dilated DenseNet core로 구성됩니다.
* Time-Frequency Mamba
모델은 하나의 Temporal Mamba layer와 하나의 Frequency Mamba layer로 구성되며, 이러한 구조를 여러 번 쌓아 T-F Mamba block을 쉽게 추가할 수 있습니다. Temporal Mamba layer는 시간 프레임을 독립적으로 처리하며, 모든 프레임은 동일한 네트워크 파라미터를 공유합니다. 입력은 단일 시간 프레임에서 주파수 변화에 따른 시퀀스이며, 이 과정에서 공간적/위치 추정(spatial/localization cue)과 관련된 상호 주파수 의존성(inter-frequency dependency)을 학습합니다. 반면, Frequency Mamba layer는 주파수를 독립적으로 처리하며, 모든 주파수는 동일한 네트워크 파라미터를 공유합니다. 입력은 단일 주파수에서 시간 변화에 따른 시퀀스이며, 이 과정에서 채널 간 정보 (inter-channel information)를 활용해 direct-path localization feature을 추정합니다.
* Output Decoder
frame rate을 줄이기 위해 average pooling module을 통과한 이후, Tanh activation이 포함된 fully connected layer를 거쳐 원하는 출력 차원으로 변환합니다. DoA 추정을 위해 공간 스펙트럼(spatial spectrum) 예측 모듈을 사용하여, 180도 선형 마이크 배열에서 모든 각도에 대해 소스의 위치를 예측할 수 있도록 오디오 데이터에서 특징을 추출하고 복잡한 관계를 학습합니다. Spatial spectrum은 0도부터 180도까지 1도 단위의 해상도를 가지며, 181-point 맵으로 구성됩니다. 모델은 출력된 spatial spectrum과 실제값(ground-truth) 간의 MSE 손실을 최소화하도록 학습됩니다.
- DoA (direction of arrival): 소스를 향한 마이크 배열의 방향 및 각도
- Spatial spectrum: DoA의 함수로 특정 DoA에서 sound source가 존재할 확률을 나타냄
2. Experimental Setting
2-1. Dataset
본 논문에서는 180도 azimuth 범위 내에서 두 개의 마이크를 이용해 소스 위치를 추정하기 위해, simulation dataset과 real-world dataset을 사용했습니다. 먼저, simulation data의 RT60은 0.2~0.6초 사이로 랜덤하게 선택하였고, 16kHz Librispeech에서 음성 신호를 가져와 gpuRIR 툴을 사용해 멀티채널 데이터를 생성하였습니다. 방 사이즈는
- Task 3: single, moving talker using a stataic mic. array
- Task 5: single, moving talker using a moving mic. array
2-2. Metrics
MAE (mean absolute error)는 예측 오류의 평균 크기를 나타내고, ACC (accuracy)는 예측이 정확히 일치하거나 특정 허용 오차 (tolerance) 범위 내에 있을 비율을 나타냅니다. 본 논문에서는 10도, 15도 오차 허용 범위에서 모델의 성능을 평가하였습니다.
3. Results & Analysis
Table 1을 보면, Mamba block을 더 많이 쌓을수록, 성능이 좋아지는 것을 확인할 수 있습니다. 이를 통해 네트워크가 깊어질수록 모델이 더욱 복잡한 localization 정보를 학습할 수 있음을 알 수 있습니다. 또한, BiMamba와 Skip connection을 각각 제거했을 때 성능이 떨어지는 것으로 보아, 이 두 구성 요소가 모델 학습에 유의미한 역할을 수행함을 알 수 있습니다.
Table 2를 보면, TF-Mamba가 FN-SSL보다 더 우수한 성능을 보이는 걸 확인할 수 있습니다. FN-SSL도 direct-path를 분석하지만, TF-Mamba는 time-frequency dependency를 더 효과적으로 포착하여 복잡한 환경에서도 더 높은 정확도를 보여줍니다. 반면에, SRP-PHAT spatial spectrum을 입력으로 사용하는 Cross3D 모델이나 magnitude spectrum와 noisy IPD를 처리하는 SALSA-Lite 모델은 노이즈가 많은 환경에서 성능이 크게 떨어지는 걸 확인할 수 있습니다.
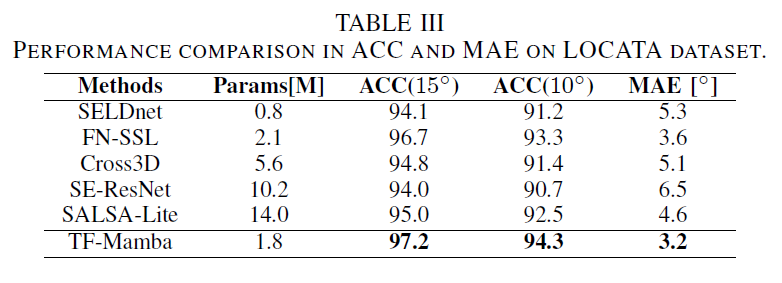
LOCATA dataset은 거의 노이즈가 없고 RT60이 0.55초로, simulation dataset에서의 낮은 SNR 환경보다 더 나은 음향 환경을 제공하기 때문에 모든 모델이 비교적 우수한 성능을 보입니다. 네트워크가 TF-Mamba보다 상대적으로 복잡한 모델인 SE-ResNet과 SALSA-Lite는 높은 MAE를 보이고, SELDnet과 같은 단순한 모델은 ACC와 MAE 면에서 대부분의 모델보다 성능이 떨어집니다. 반면에, TF-Mamba는 다른 방법들보다 더 높은 ACC와 낮은 MAE를 보이는 등 세밀한 위치 정보를 잘 포착합니다. 또한, TF-Mamba는 움직이는 음원이 급격하게 방향을 바꿀 때 발생하는 over-smoothing problem을 피하면서 실제 환경에서도 뛰어난 localization 성능을 보입니다.
- Over-smoothing problem: 네트워크가 반복해서 정보를 통합하여 feature가 지나치게 평활화되는 현상으로, local feature를 잃어버리고 global feature만 남는 문제를 말함
Reference
[1] Xiao, Yang, and Rohan Kumar Das. "TF-Mamba: A Time-Frequency Network for Sound Source Localization." arXiv preprint arXiv:2409.05034 (2024).
[2] Wang, Yabo, Bing Yang, and Xiaofei Li. “FN-SSL: Full-band and narrow-band fusion for sound source localization,” in Proc. Interspeech, 2023, pp. 3779–3783.
추가로, audio deepfake detection에 Mamba를 적용한 논문을 보고싶으시다면, 아래 글을 참고해주세요 :)
[논문 정리] RawBMamba: End-to-End Bidirectional State Space Model for Audio Deepfake Detection
목차0. Summary1. Background2. Proposed method 2-1. Short-range feature representation 2-2. Bidirectional state space model3. Experiments 3-1. Dataset & Metrics 3-2. Analysis4. Memo 0. Summaryfake audio를 가려내는데 쓰이는 f
sunny-archive.tistory.com


