목차
2-1. Short-range feature representation
2-2. Bidirectional state space model
0. Summary
fake audio를 가려내는데 쓰이는 fake artefact는 short/long range segment 어디에서든 존재할 수 있습니다. 따라서, fake audio detection task에서는 local/global information을 모두 활용하는 것이 좋습니다. 본 논문 [1]은, audio deepfake detection을 위해 short/long range discriminative information을 모두 추출하는 end-to-end bidirectional state space model (RawBMamba)를 제안합니다. 저자들은 short range feature를 추출하기 위해, parametrizable sinc layer와 여러 convolutional layer 사용하였습니다. 그리고 Mamba의 unidirectional modeling problem을 해결하기 위해, bidirectional Mamba를 설계하여 long range feautre information을 추출합니다. 마지막으로, audio context representation을 향상하고 short/long range information을 합치는 bidirectional fusion module을 소개합니다. ATSVspoof2021 LA dataset에서 Rawformer 대비 RawMamba는 34.1% 개선된 성능을 보여줍니다.
1. Background
Mamba의 SSM은 제어 이론에서 사용되는 state space model을 기반으로 정의됩니다. 원래는 continuous한 변수를 가정해서 사용하는 방정식이기 때문에, 딥러닝 모델에 사용하기 위해서는 변수를 discrete 하게 만들어야 합니다. 먼저 hidden state를 이용해 1-D function 또는 sequence를 매핑합니다.
* State Transition parameter
현재 state가 다음 state로 어떻게 업데이트 될지 결정하며 sequence의 temporal pattern을 학습하는데 씁니다.
* Projection parameter
state를 output으로 변환하기 위해 사용합니다.
* Continuous-time SSM
* Discretization rule
Mamba에서는 continuous한 변수를 discrete한 변수로 만들어주기 위해 zero-order hold (ZOH) 방식을 사용합니다. time scale parameter인
* Discrete-time SSM
아래는 step size
model은 global convolution을 통해 output을 계산합니다. SSM은 linear한 성질을 가지므로, output sequence

2. Proposed Method
논문에서 다루는 기본적인 용어를 짚고 넘어가겠습니다. short-range feature는 이웃한 데이터 간 correlation이나 context를 반영한 feature를 말합니다. 그리고 long-range feature는 데이터 내에서 멀리 떨어진 information 간 correlation 또는 context를 반영하는 feature를 의미합니다.
2-1. Short-range feature representation

최근 연구에서는 raw waveform을 활용해 standard filter process를 근사하는 방식으로 학습하기 위해, trainable neural layer를 사용하는 추세인데요. 본 논문에서 제안한 RawBMamba도 high-level short-range feature mapping (HFM)을 학습하기 위해, RawNet2의 front-end를 변형해서 사용하였습니다. 모델의 입력은 raw-waveform으로, 앞단에 등장하는 parametric sinc function은 bandpass filter를 구현하는데 사용되는데 raw waveform으로부터 spectral-temporal feature들을 추출하고 low-level feature map (LFM),
- squeeze operation: 각 feature map에 대한 전체 정보를 요약
- excitation operation: 요약한 정보를 바탕으로 각 feature map의 중요도를 scale 해줌
마지막으로, HFM이 time축, frequency 축에 따라 flatten되면서 two-dimensional short-range feature sequence,
2-2. Bidirectional state space model
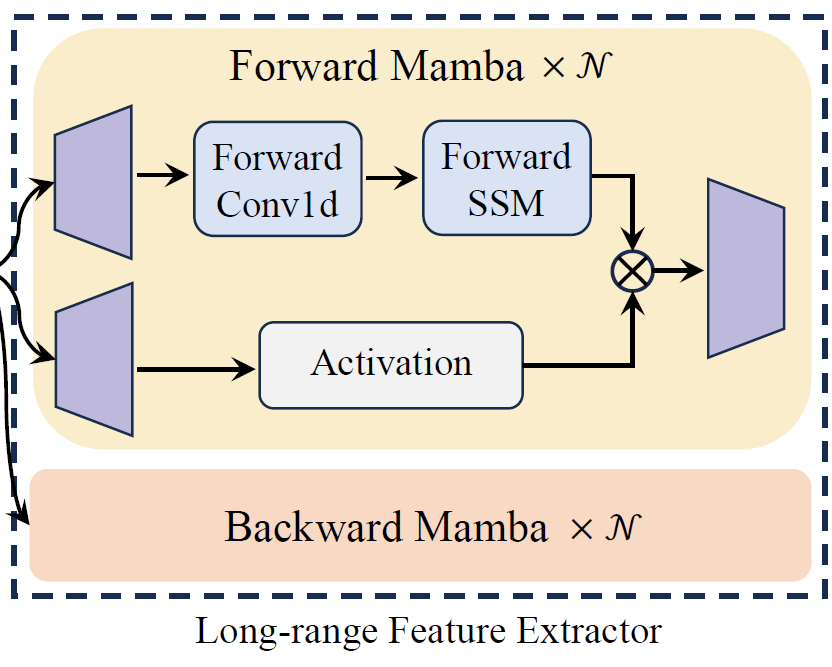
Mamba [2]에서 제안한 selective SSM은 가장 관련있는 information을 선택하고 관련 없는 건 filtering out하여 모델이 효율적으로 long-range feature를 잘 학습하도록 도와줍니다. 하지만 Mamba의 Markovian 특성으로 인해, unidirectional 방식으로만 long-range feature를 모델링할 수 있었습니다. 그렇기 때문에 contextual information을 잘 학습하지 못한다는 한계를 가지고 있었고, 이러한 문제를 해결하기 위해, 본 논문에서는 bidirectional Mamba를 설계합니다.
* Bidirectional Mamba

Bidirectional Mamba는 front-end에서 구한 short-range feature
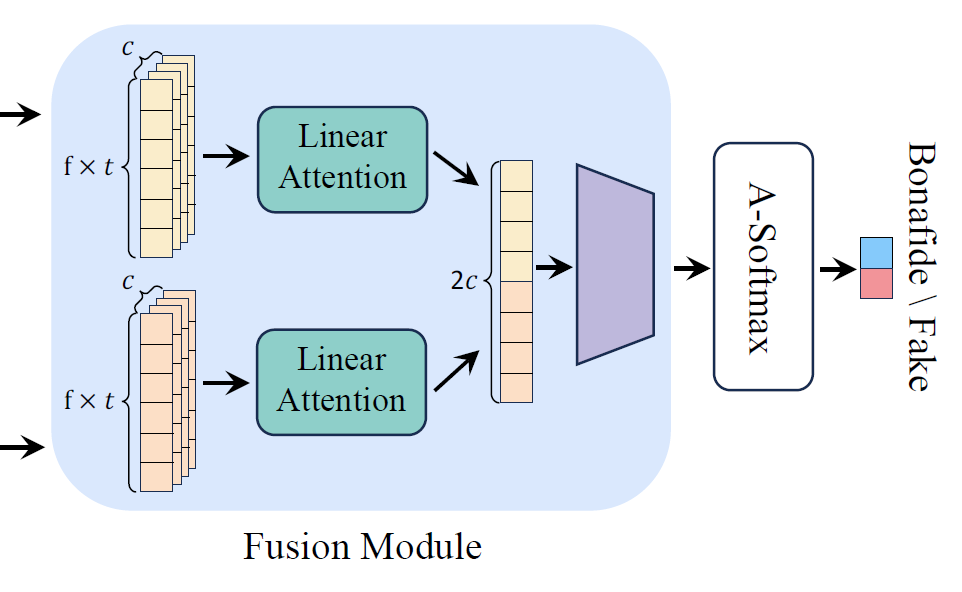
* Bidirectional feature fusion block
key information을 추출하기 위해, 각각의 unidirectional long-range feature에 linear self-attention operation을 적용합니다. 그후, bidirectional feature를 fusion하기 위해 concatenation을 수행합니다. 이렇게 얻은 short/long range speech feature
3. Experiments
3-1. Dataset & Metrics
모델의 effectiveness와 generalizability를 평가하기 위해, ASVspoof2019 LA (19LA), ASVspoof2021 LA (21LA), ASVspoof2021 DF (21DF)에 대한 테스트를 수행하였습니다. 19LA는 19가지 알고리즘(A01-A19)을 사용하는 3가지 유형의 fake attack(TTS, VC) 포함하고 있습니다. 21LA는 Voice over IP와 Public Switched Telephone Network 같은 전화 시스템을 통해 얻은 authentic 및 spoofed voice를 포함합니다. 21DF는 다양한 media codec으로 distortion이 발생한 authentic 및 spoofed voice 등 실제 데이터를 포함합니다.
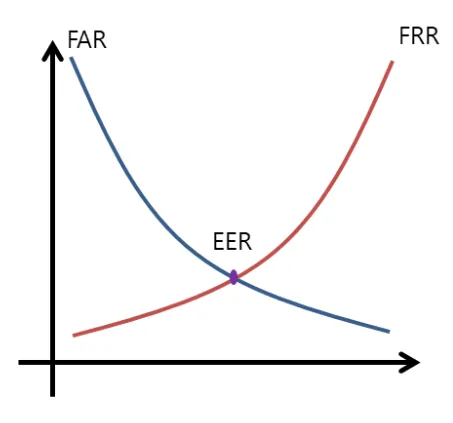
모델 평가지표로 equal error rate (EER)과 minimum t-DCF를 사용하였습니다. EER은 FAR (False alarm rate)이랑 FRR (False reject rate)이 같아지는 비율을 나타냅니다. Speaker verification (SV) task에 주로 사용되는 평가지표 min DCF는 아래와 같이 정의됩니다. min DCF는 SV system의 단독 성능을 평가할 때 쓰이고, min t-DCF는 SV system이 다른 system과 결합되어 있는 상태에서 성능을 평가할 때 사용합니다.
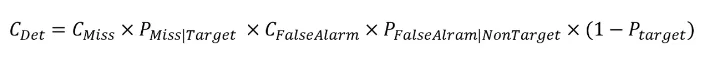
3-2. Analysis
1) 다양한 configuration에서 RawMamba 성능 분석
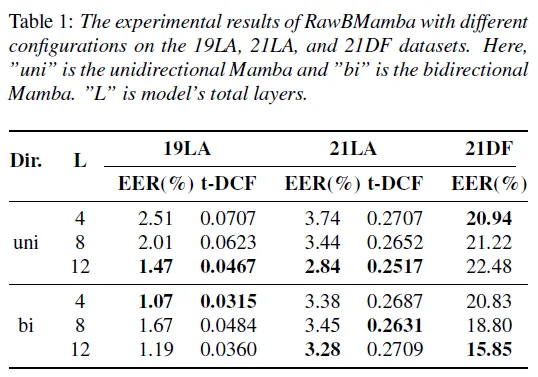
전반적으로 bidirectional Mamba model이 unidirectional Mamba model 보다 더 성능이 좋은 것을 확인할 수 있습니다. 이를 통해, unidirectional Mamba에서 contextural information이 효율적으로 학습되지 않는 문제를 RawBMamba가 일부 완화한 것을 알 수 있습니다. 또한, bidirectional model이 layer 개수가 더 적을 때 똑같은 조건에서의 unidirectional Mamba model 보다 더 개선된 것으로 보았을 때, bidirectional feature fusion module이 forward/backward long-range feature information을 잘 활용한다는 걸 알 수 있습니다. 하지만, 21DF dataset에서는 layer 수가 줄어들수록 성능이 저하되는 현상이 관찰되었습니다. 이는 19LA dataset이 깨끗한 환경에서 녹음된 것에 반해, 21DF는 실제 잡음 환경을 모사한 데이터이기 때문에 발생하는 현상이라고 볼 수 있습니다.
2) 다양한 fusion method에서 RawMamba 성능 분석
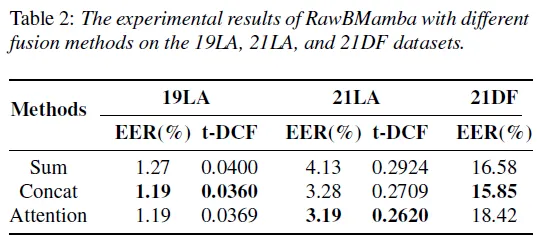
자주 쓰이는 3가지 fusion method (summation, concatenation, cross-attention mechanism)의 성능을 비교한 결과입니다. 먼저, concatenation이 전반적으로 다른 두 개의 fusion method 보다 더 좋은 성능을 보여주는 걸 알 수 있습니다. 이런 결과가 나온 이유는 가능한 많은 time-frequency information을 통합하는 것이 time-frequency domain 상에서 2개의 unidirectional long-range feature에 대한 key information을 추출하는데 도움이 되기 때문입니다. 두 번째로, cross-attention mechanism은 21DF dataset에서 성능이 별로 좋지 않은 걸 확인할 수 있습니다. 이는 key information에 너무 집중한 나머지, time-frequency information에 손실이 있기 때문에, domain 바깥의 data에 대한 generalization이 떨어지는 것이라고 볼 수 있겠습니다. 마지막으로, Summation fusion method는 21DF dataset에서 그럭저럭 괜찮은 결과를 보여줍니다. RawBMamba는 2개의 unidirectional long-range feature의 모든 time-frequency domain information에 대해 간단한 summation operation을 포함하고 있습니다. 간단한 연산임에도 모든 time-frequency domain에 걸쳐 information을 밸런싱하는 potential regularization effect로서 작용하므로 다른 method와 비교했을 때 성능이 크게 떨어지지 않습니다.
3) 다른 end-to-end model과 비교
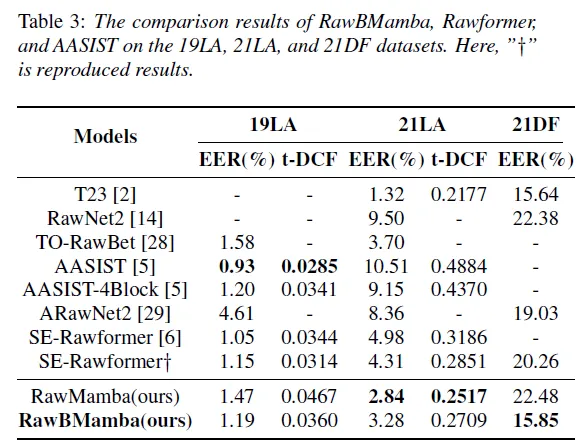
RawMamba는 12 layer unidirectional Mamba model이고 RawBMamba는 12 layer bidirectional Mamba model로 각 방향에 6 layer를 포함하고 있습니다. 21LA dataset에서 실험 결과를 분석해보면, SE-Rawformer (4.98)와 비교했을 때 RawBMamba (3.28)로 34.1% 성능 향상을 이끌어냈습니다. 이를 통해, Mamba가 Transformer 보다 더 효율적으로 long-range feature information을 학습한다는 걸 알 수 있습니다. 추가로, 21 DF dataset에서 실험 결과를 분석해보면 single system RawBMamba가 multi-system score fusion T23과 매우 근접한 성능을 보인다는 걸 확인할 수 있습니다. 이러한 결과는 다른 model과 비교했을 때 RawBMamba가 전혀 모르는 새로운 형태의 음성 위조 방법에 노출되더라도 detection 성능을 꽤 유지한다는 걸 보여줍니다.
4) RawBMamba와 Rawformer 비교

19LA test dataset에 대해 final feature를 추출하여 high dimensional data를 시각화한 결과입니다. Rawformer와 비교했을 때, RawBMamba로 얻은 feature가 더 식별력이 좋은 걸 한 눈에 알 수 있습니다. 특히 Mamba의 feature는 여러 개의 non-overlapping 곡선 패턴을 나타내며, 다양한 attack type을 구분할 수 있는 풍부한 특징을 포함하고 있음을 알 수 있습니다. 결론적으로, Mamba는 audio deepfake detection 모델의 backbone으로 활용되기에 충분한 가능성을 가지고 있습니다.
4. Memo
일반적인 BLSTM layer는 처리가 끝날 때마다 linear layer가 붙어서 forward, backward 결과를 중간중간마다 섞어주는데 제안한 모델의 경우 forward, backward 결과를 마지막에서야 합쳐주고 있기 때문에, feature가 충분하게 잘 조합이 되었는지 의문이 듭니다.
HFM을 flatten할 때를 살펴봅시다. time 축 기준으로 붙이면 frequency 축 흐름이 일정하지 않고, frequency 축으로 붙이자니 time 축 흐름이 일정하지 않는 문제가 발생합니다.
Reference
[1] Y. Chen et al., “RawBMamba: End-to-End Bidirectional State Space Model for Audio Deepfake Detection,” INTERSPEECH, 2024, doi: https://doi.org/10.21437/interspeech.2024-698.
[2] Gu, Albert, and Tri Dao. "Mamba: Linear-time sequence modeling with selective state spaces." arXiv preprint arXiv:2312.00752 (2023).


