목차
1. Multi-Task Learning이란?
Multi-Task Learning (MTL)은 여러 개의 learning task를 동시에 해결하면서, 각 task 간 관계를 활용하는 머신러닝의 한 분야입니다. 서로 관련된 여러 task의 training signal에 포함된 도메인 정보를 inductive bias로 사용하여 모델의 일반화 성능을 향상시킵니다.
2. Motivation
(1) 여러 개의 task를 함께 수행 → 한 task에서 배운 정보가 다른 task를 학습하는 데 도움 됨
- 적용 예시 : 얼굴 인식 모델을 학습할 때 "나이 예측"을 추가로 학습하면, 얼굴 특징을 더 정밀하게 구분할 수 있어 얼굴 인식 성능도 향상될 수 있음
(2) 보조 task가 제공하는 inductvie bias를 도입한 inductive transfer는 모델 성능 향상에 긍정적인 영향을 줌
- inductive transfer: 모델이 학습된 데이터를 바탕으로 일반적인 패턴을 찾아내도록 돕는 과정
- inductive bias: 모델이 학습할 때 특정 방향으로 일반화하도록 유도하는 사전 지식 또는 가정
- inductive bias의 일반적인 형태인 L1 Regularization: weight 값 중에서 중요하지 않은 값을 0에 가깝게 만들어 모델이 더 단순한, sparse한 해를 찾도록 유도 → 모델이 필요로 하지 않는 feature를 자동으로 무시하고 학습에 필요한 중요 정보만 사용하여 더 일반화된 성능을 기대할 수 있음
3. Method
(1) Feature 기반 MTL
- 여러 task에서 공통으로 사용할 수 있는 feature를 학습하는 방식
- 모델이 서로 다른 task를 수행하면서 학습에 유용한 공통된 feature를 찾도록 함
(2) Parameter 기반 MTL
- 모델의 파라미터 (e.g. weight)를 공유하여 여러 task가 서로 도움을 주고받도록 학습
- 하나의 task에서 학습한 weight가 다른 task의 weight를 학습하는 데 도움을 줌
(3) Instance (데이터 샘플) 기반 MTL
- 하나의 task에서 유용했던 데이터 샘플을 다른 task 학습에도 활용하는 방식
- 각 task에서 중요한 데이터를 찾아 공유
+) Deep learning에서 Multi-Task Learning을 적용하는 2가지 방법
Hard parameter sharing

- 모든 task가 동일한 hidden layer를 공유하되, 각각의 task는 독립적인 output layer를 가짐
- 동일한 feature extraction을 공유하므로 학습 효율이 높아짐
Soft parameter sharing
- 각 task는 자체적인 모델을 가지며, 각 모델은 고유한 파라미터를 가짐
- Task 간 파라미터 차이를 최소화하기 위해 regularization을 사용하여 모델 간 파라미터들이 유사해지도록 학습
4. 장단점
MTL 장점
- 하나의 task를 학습하면서 얻은 도메인 정보를 다른 task를 효과적으로 학습하는데 활용할 수 있음
- 일반화된 shared representation을 학습할 수 있음
- 여러 task를 동시에 학습하기 때문에, 연산량 면에서 효율적일 수 있음
MTL 단점
- 여러 task 간 균형을 맞추는 게 어려울 수 있음
- task 간 학습 난이도가 차이나는 경우 학습이 잘 이루어지지 않을 수 있음
5. Speech Domain 적용 사례
MTL 기법을 활용한 MSDET [3] 논문은 여러 개의 마이크를 활용하여 화자의 공간 상 위치 정보를 효과적으로 활용하는 방법을 제시합니다. LBT (Location-Based Training)는 화자의 위치 정보를 얻는 기법으로, Localization task에서의 소스 간 순열 문제 (permutation ambiguity)를 해결하기 위해, 방위각 (azimuth angle) 의 순서와 화자의 거리 (speaker distance)를 사용합니다. 여기서 얻은 위치 정보를 가지고 MTL기법을 적용함으로써, Multi-Channel Speaker Separation 성능을 추가로 향상시킬 수 있습니다.
논문에서 Multitask loss는 Speaker Separation과 DoA estimation, 각각의 task에 대한 loss의 weighted average 꼴로 정의됩니다. 여기서 Speaker Separation Loss는 주파수 도메인에서 생성된 신호와 ground-truth 간 L1 Loss를 사용하여 계산되고, DoA estimation Loss는 DoA estimator의 출력과 ground-truth DoA 간 Cross Entropy Loss로 계산됩니다.

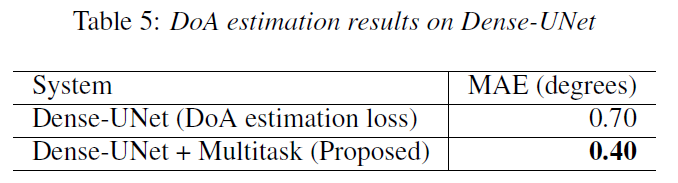
실험 결과, Speech Separation 성능과 DoA 성능이 전반적으로 향상된 것을 관찰할 수 있습니다.
Reference
[2] W. Ahmad, “Multi-Task Machine Learning.” Accessed: Feb. 27, 2025. [Online]. Available: https://yunshengb.com/wp-content/uploads/2017/11/Multi-Task-Machine-Learning.pdf
[3] R. Hartanto, Sakriani Sakti, and K. Shinoda, “MSDET: Multitask Speaker Separation and Direction-of-Arrival Estimation Training,” Interspeech 2022, pp. 2170–2174, Sep. 2024, doi: https://doi.org/10.21437/interspeech.2024-2537.
'AI 개념 및 구현 > 머신러닝 & 딥러닝' 카테고리의 다른 글
| npz compressed를 이용한 데이터 로드 속도 개선 (Feat. 학습 속도를 부스팅하기 위한 다양한 시도들) (0) | 2024.12.13 |
|---|---|
| ZOH (Zero-order hold):Mamba의 discretization rule (1) | 2024.10.17 |

